
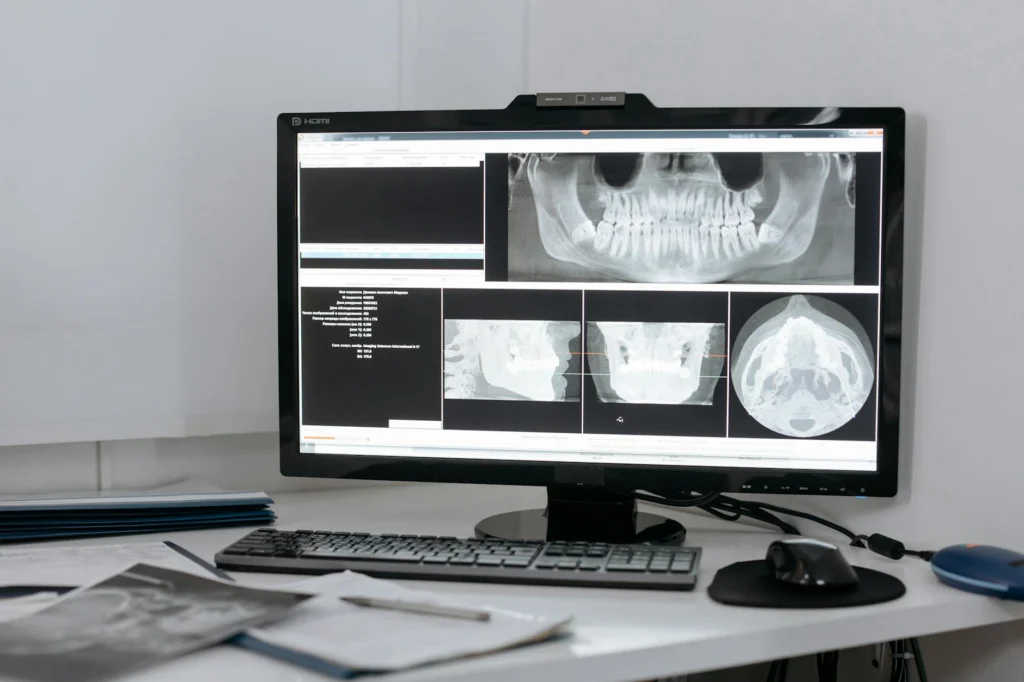
Les images deepfake médical ont franchi un seuil critique. Une étude de mars 2026 publiée dans Radiology[s] a révélé que les radiographies générées par IA sont désormais suffisamment réalistes pour tromper à la fois les radiologues et les systèmes d’IA conçus pour les aider. Quand les médecins ne savaient pas que de fausses images étaient mélangées, moins de la moitié les ont détectées. Même prévenus, leur précision n’atteignait que 75%.
Ce n’est pas un risque théorique. La technologie pour créer des images deepfake médical est désormais accessible à quiconque possède un abonnement ChatGPT. Et l’infrastructure destinée à stocker et partager les scanners médicaux présente des failles de sécurité qui persistent depuis des décennies.
Images Deepfake Médical : Ce que l’Étude a Révélé
Dix-sept radiologues de 12 institutions dans six pays[s] ont examiné 264 images radiographiques. La moitié étaient de vrais scanners cliniques. L’autre moitié était générée par IA, certaines par ChatGPT (GPT-4o) et d’autres par RoentGen, un modèle open-source développé à Stanford.
Dans la première phase, les radiologues n’étaient pas informés que l’étude impliquait des fausses images. On leur demandait simplement d’évaluer la qualité d’image et de noter toute anomalie. Seulement 41% ont exprimé des inquiétudes sur la possible présence d’images deepfake médical. Les autres n’ont rien trouvé d’anormal.
Dans la deuxième phase, les radiologues étaient informés que certaines images étaient synthétiques et devaient distinguer le vrai du faux. Leur précision moyenne était de 75%, ce qui signifie qu’une image deepfake médical sur quatre passait encore inaperçue. Les scores individuels variaient de 58% à 92%. Les années d’expérience ne faisaient aucune différence. Un résident de première année obtenait des résultats similaires à un vétéran avec quatre décennies d’expérience.
Les modèles d’IA ne s’en sortaient guère mieux. Quatre grands modèles de langage (GPT-4o, GPT-5, Gemini 2.5 Pro, et Llama 4 Maverick) ont été testés sur les mêmes images. Leur précision variait de 57% à 85%[s]. Même GPT-4o, le modèle qui créait les fausses images, ne pouvait pas identifier de manière fiable ses propres productions.
Pourquoi Cela Importe pour les Patients
Quand les radiologues devaient diagnostiquer les conditions montrées dans les images, leur précision diagnostique était de 92,4% pour les radiographies deepfake médical[s], presque identique aux 91,3% pour les vrais scanners. En d’autres termes, les médecins croyaient non seulement que les fausses images étaient vraies ; ils diagnostiquaient avec confiance des conditions médicales dans des images qui ne représentaient aucun patient réel.
Les implications sont doubles. Une image de fracture fabriquée pourrait soutenir une réclamation d’assurance frauduleuse ou un procès. Un scanner manipulé montrant un poumon sain pourrait cacher un vrai cancer. « Cela crée une vulnérabilité à enjeux élevés pour les litiges frauduleux si, par exemple, une fracture fabriquée pouvait être indiscernable d’une vraie », a déclaré l’auteur principal Mickael Tordjman[s], radiologue au Mount Sinai à New York.
La Barrière d’Entrée s’est Effondrée
Ce qui rend ce moment différent, c’est l’accessibilité. Les premières images deepfake médical nécessitaient une expertise spécialisée en apprentissage automatique. En 2019, des chercheurs de l’Université Ben-Gurion ont démontré CT-GAN[s], un système qui pouvait injecter ou supprimer des tumeurs de scanners CT 3D. Cette attaque trompait les radiologues dans 99% des cas, mais la construire nécessitait d’entraîner des réseaux de neurones personnalisés sur des données médicales.
Aujourd’hui, générer des radiographies anatomiquement plausibles ne nécessite rien de plus qu’une commande en langage naturel[s] à un chatbot commercial. La barrière technique a effectivement disparu.
Les Réseaux Hospitaliers ne sont pas Prêts
L’infrastructure d’imagerie médicale elle-même aggrave le problème. DICOM, le protocole standard pour stocker et partager les scanners, a été conçu pour l’interopérabilité, pas la sécurité. Une enquête de 2023 par la société de cybersécurité Aplite[s] a trouvé plus de 3 800 serveurs DICOM exposés sur Internet ouvert dans 110 pays, divulguant des données sur 16 millions de patients. Moins de 1% de ces serveurs utilisaient des mesures de sécurité efficaces.
Les chercheurs CT-GAN de 2019 ont démontré un vecteur d’attaque pratique[s] : avec permission, ils ont pénétré un vrai réseau hospitalier et intercepté chaque scanner pris par un appareil CT. Les réseaux hospitaliers internes transmettent souvent les scanners sans chiffrement car ils n’étaient historiquement pas connectés à Internet. Cette hypothèse est de plus en plus dépassée.
Que Peut-on Faire
Les chercheurs recommandent une défense en couches. Les mesures de protection proposées incluent des filigranes invisibles[s] intégrés dans les images au moment de la capture et des signatures cryptographiques liées au technologue qui a pris le scanner. Celles-ci créeraient une chaîne de custody qui rend détectable la manipulation post-capture.
« Nous ne voyons potentiellement que la pointe de l’iceberg », a averti Tordjman[s]. « L’étape logique suivante dans cette évolution est la génération par IA d’images 3D synthétiques, comme les CT et IRM. Établir des jeux de données éducatives et des outils de détection maintenant est critique. » L’équipe d’étude a publié un jeu de données deepfake sélectionné avec des quiz interactifs[s] pour aider à entraîner les radiologues.
La spécialiste en intégrité d’image Elisabeth Bik l’a dit clairement : « Cela soulève des inquiétudes non seulement pour l’intégrité de la recherche, mais aussi pour les workflows cliniques, les réclamations d’assurance et les contextes légaux où les preuves d’imagerie sont utilisées. »[s]
Les signes révélateurs existent, pour l’instant. Les images deepfake médical semblent souvent « trop parfaites », avec des os trop lisses, des colonnes vertébrales anormalement droites, et des lignes de fracture suspecieusement nettes. Mais à mesure que les modèles s’améliorent, même ces indices disparaîtront.
Une étude multicentrique publiée dans Radiology en mars 2026[s] quantifie ce que la communauté d’imagerie redoutait : les images deepfake médical générées par des modèles de langage volumineux commercialement disponibles sont désormais indiscernables des radiographies authentiques à des taux cliniquement pertinents. Ni les lecteurs humains ni les LLM multimodaux n’ont réussi une discrimination fiable, et la barrière technique pour produire ces faux a chuté près de zéro.
Images Deepfake Médical : Conception et Résultats de l’Étude
L’étude rétrospective de précision diagnostique[s], menée entre avril et août 2025, a recruté 17 radiologues de 12 institutions dans six pays, avec une expérience allant de 0 à 40 ans. Ils ont évalué deux jeux de données non-chevauchants comprenant 264 images au total.
Le jeu de données 1 contenait 77 radiographies authentiques appariées avec 77 images synthétiques générées par GPT-4o à travers plusieurs régions anatomiques (thorax, extrémités, colonne vertébrale). Le jeu de données 2 contenait 55 radiographies thoraciques authentiques et 55 radiographies thoraciques synthétiques produites par RoentGen, un modèle de diffusion latente affiné sur les radiographies thoraciques[s] développé par les chercheurs de Stanford Medicine.
L’étude s’est déroulée en trois phases. En phase 1, les radiologues, aveugles au but de l’étude, évaluaient la qualité d’image sur une échelle de Likert et fournissaient des diagnostics. Seulement 41% (7 sur 17) ont spontanément noté que des images deepfake médical pourraient être présentes. La précision diagnostique était de 91,3% pour les radiographies authentiques et 92,4% pour les synthétiques[s], confirmant que les images deepfake médical étaient non seulement visuellement convaincantes mais diagnostiquement cohérentes.
En phase 2, informés que des images synthétiques étaient présentes, les radiologues ont atteint une précision moyenne de 75% (IC 95% : 68-81%) sur le jeu de données GPT-4o. La performance individuelle variait de 58% à 92%. La sensibilité groupée était de 69,1% et la spécificité de 80,4%. En phase 3, la précision sur le jeu de données RoentGen était de 70% (IC 95% : 62-78%), sans différence statistiquement significative par rapport à la performance GPT-4o (P = .07).
Aucune corrélation n’a été trouvée entre les années d’expérience et la précision de détection.[s] Les radiologues musculosquelettiques ont significativement surpassé les autres sous-spécialistes, probablement parce que la morphologie osseuse fournit plus d’indices structurels discrets que les motifs de tissus mous.
Performance des LLM comme Discriminateurs
Quatre LLM multimodaux ont été évalués sur la même tâche de classification. GPT-4o a atteint 85% de précision sur ses propres images synthétiques[s] et 75,5% sur les images RoentGen. GPT-5 a marqué 82,5% et 89,1% respectivement. Llama 4 Maverick (59%, 52%) et Gemini 2.5 Pro (56%, 57%) ont performé substantiellement moins bien, dans certains cas près du niveau du hasard. La différence entre les modèles OpenAI et les concurrents était statistiquement significative (tous P < .001).
Le fait que GPT-4o ne pouvait pas identifier de manière fiable sa propre production est significatif. Il suggère que le processus de génération n’intègre pas d’artefacts facilement récupérables : le modèle génère à partir de la même distribution apprise de caractéristiques radiographiques, rendant la discrimination un problème fondamentalement plus difficile que la génération.
Des GANs aux LLM : Le Point d’Inflexion de l’Accessibilité
L’étude actuelle représente un point d’inflexion dans l’évolution des images deepfake médical. L’IA générative en imagerie médicale a évolué des GANs aux modèles basés sur la diffusion[s], et maintenant aux LLM à usage général qui acceptent des commandes en langage naturel. Chaque génération a abaissé l’expertise requise.
Le framework CT-GAN de 2019 de l’Université Ben-Gurion a démontré la menace en imagerie volumétrique. Mirsky et al. ont utilisé un GAN conditionnel 3D pour injecter et supprimer le cancer du poumon des scanners CT[s], réalisant des manipulations qui s’exécutaient en millisecondes et trompaient les radiologues dans une évaluation aveugle. Trois radiologues ont mal diagnostiqué 99% des scanners avec des tumeurs injectées et 94% de ceux avec des tumeurs supprimées.[s] Même après avoir été informés du sabotage, les taux de mauvais diagnostic restaient à 60% et 87% respectivement.
Mais CT-GAN nécessitait d’entraîner des architectures cGAN personnalisées sur des jeux de données médicaux sélectionnés, un pipeline non-trivial. L’étude 2026 montre qu’une tromperie 2D comparable est désormais réalisable via un appel API commercial. La surface d’attaque s’est élargie des acteurs au niveau étatique et adversaires bien financés à essentiellement n’importe qui.
Vulnérabilités de l’Infrastructure : DICOM et PACS
L’infrastructure d’imagerie elle-même reste mal défendue. DICOM (Digital Imaging and Communications in Medicine), le standard universel pour le stockage et la transmission d’images médicales, a été conçu pour l’interopérabilité, pas la sécurité[s]. Les serveurs PACS (Picture Archiving and Communication Systems) fonctionnent fréquemment avec une authentification minimale et des communications internes non chiffrées.
Un audit 2023 par Aplite présenté au Black Hat Europe[s] a identifié plus de 3 800 serveurs DICOM exposés dans plus de 110 pays, avec 16 millions de dossiers patients et 43 millions de dossiers de santé accessibles depuis Internet ouvert. Moins de 1% implémentaient des mesures de sécurité efficaces. Les chercheurs ont aussi démontré un nouveau vecteur d’attaque pour sabotage de données dans les images médicales existantes sur ces systèmes exposés.
L’équipe CT-GAN a démontré une attaque d’interception homme-du-milieu sur un réseau hospitalier en direct[s], capturant chaque scanner d’un appareil CT. Les réseaux de radiologie internes supposaient historiquement une isolation de l’Internet, mais la migration cloud et les exigences d’accès distant ont érodé cette hypothèse.
Stratégies d’Atténuation
Les auteurs de l’étude proposent une défense multi-couches[s] : filigranes invisibles intégrés lors de l’acquisition d’image, signatures cryptographiques liées au technologue attachées à la capture, journalisation d’audit PACS pour les motifs d’accès aux enregistrements, et détection d’anomalie pour les modifications inhabituelles d’enregistrements.
Les radiologues de l’étude ont identifié plusieurs indices morphologiques dans les images deepfake médical de génération actuelle : artefacts de symétrie bilatérale, motifs de bruit uniformes (manquant le bruit spatialement variable du vrai matériel détecteur), cortex osseux trop lisse, alignement vertébral anormalement régulier, et lignes de fracture qui semblent « trop nettes », affectant souvent seulement une surface corticale plutôt que se propageant à travers la section transversale complète de l’os.
Cependant, ces signatures sont spécifiques au modèle et diminueront probablement à mesure que les architectures génératives s’améliorent. « Nous ne voyons potentiellement que la pointe de l’iceberg », a noté Tordjman[s]. « L’étape logique suivante dans cette évolution est la génération IA d’images 3D synthétiques, comme CT et IRM. »
Elisabeth Bik, spécialiste en intégrité d’image, a qualifié les résultats de « à la fois troublants et pas très surprenants »[s], notant que les implications s’étendent au-delà de la pratique clinique à « l’intégrité de la recherche, les réclamations d’assurance et les contextes légaux où les preuves d’imagerie sont utilisées ». L’équipe d’étude a publié un jeu de données éducatif sélectionné à noneedanick.github.io/DeepFakeXRay[s] pour former les cliniciens à la détection.
Le défi fondamental est asymétrique : générer un deepfake convaincant est computationnellement bon marché et devient moins cher. Le détecter nécessite soit une provenance cryptographique (qui demande une refonte d’infrastructure) soit une médecine légale visuelle (que l’étude montre non fiable même parmi les experts). La fenêtre pour une défense proactive se rétrécit.



