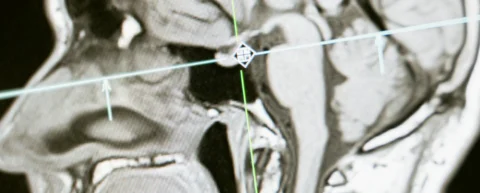
Deepfake Medizin hat eine kritische Schwelle überschritten. Eine im März 2026 in Radiology veröffentlichte Studie[s] fand heraus, dass KI-generierte Röntgenbilder mittlerweile realistisch genug sind, um sowohl Radiologen als auch die KI-Systeme zu täuschen, die ihnen helfen sollen. Als Ärzte nicht wussten, dass gefälschte Bilder eingemischt waren, erkannten weniger als die Hälfte sie. Selbst wenn gewarnt, erreichte ihre Genauigkeit nur 75%.
Das ist kein theoretisches Risiko. Die Technologie zur Erstellung von Deepfake Medizin ist nun jedem mit einem ChatGPT-Abonnement zugänglich. Und die Infrastruktur zum Speichern und Teilen medizinischer Scans weist Sicherheitslücken auf, die seit Jahrzehnten bestehen.
Deepfake Medizin: Was die Studie Herausfand
Siebzehn Radiologen aus 12 Institutionen in sechs Ländern[s] wurden 264 Röntgenbilder gezeigt. Die Hälfte waren echte klinische Scans. Die andere Hälfte wurde von KI generiert, einige von ChatGPT (GPT-4o) und andere von RoentGen, einem Open-Source-Modell, das in Stanford entwickelt wurde.
In der ersten Phase wurden die Radiologen nicht darüber informiert, dass die Studie Fälschungen beinhaltete. Sie wurden einfach gebeten, die Bildqualität zu bewerten und Ungewöhnliches zu notieren. Nur 41% äußerten Bedenken, dass KI-generierte Deepfake Medizin Bilder vorhanden sein könnten. Der Rest sah nichts Falsches.
In der zweiten Phase wurde den Radiologen gesagt, dass einige Bilder synthetisch waren, und sie sollten echt von falsch unterscheiden. Ihre durchschnittliche Genauigkeit betrug 75%, was bedeutet, dass eines von vier Deepfake Medizin Bildern immer noch durchschlüpfte. Individuelle Werte reichten von 58% bis 92%. Jahre der Erfahrung machten keinen Unterschied. Ein Assistenzarzt im ersten Jahr schnitt ungefähr so gut ab wie ein Veteran mit vier Jahrzehnten im Feld.
KI-Modelle schnitten nicht viel besser ab. Vier große Sprachmodelle (GPT-4o, GPT-5, Gemini 2.5 Pro und Llama 4 Maverick) wurden auf denselben Bildern getestet. Ihre Genauigkeit reichte von 57% bis 85%[s]. Selbst GPT-4o, das Modell, das die Fälschungen erstellte, konnte seine eigene Ausgabe nicht zuverlässig identifizieren.
Warum das für Patienten Wichtig ist
Als Radiologen gebeten wurden, Zustände zu diagnostizieren, die in den Bildern gezeigt wurden, betrug ihre diagnostische Genauigkeit 92,4% für die KI-generierten Röntgenbilder[s], nahezu identisch mit den 91,3% für echte Scans. Mit anderen Worten, Ärzte glaubten nicht nur, dass die Fälschungen echt waren; sie diagnostizierten selbstbewusst medizinische Zustände in Bildern, die keinen echten Patienten darstellten.
Die Auswirkungen schneiden in beide Richtungen. Ein fabriziertes Frakturbild könnte einen betrügerischen Versicherungsanspruch oder Rechtsstreit unterstützen. Ein manipulierter Scan, der eine klare Lunge zeigt, könnte echten Krebs verbergen. „Das schafft eine Hochrisiko-Verwundbarkeit für betrügerische Rechtsstreitigkeiten, wenn zum Beispiel eine fabrizierte Fraktur von einer echten ununterscheidbar wäre“, sagte Hauptautor Mickael Tordjman[s], Radiologe am Mount Sinai in New York.
Die Eintrittsbarriere ist Zusammengebrochen
Was diesen Moment anders macht, ist die Zugänglichkeit. Frühere Deepfake Medizin Bilder erforderten spezialisierte Maschinenlern-Expertise. 2019 demonstrierten Forscher der Ben-Gurion-Universität CT-GAN[s], ein System, das Tumoren in 3D-CT-Scans injizieren oder entfernen konnte. Dieser Angriff täuschte Radiologen in 99% der Fälle, aber sein Bau erforderte das Training benutzerdefinierter neuronaler Netzwerke auf medizinischen Daten.
Heute erfordert die Generierung anatomisch plausibler Radiographien nichts weiter als eine natürlichsprachliche Eingabe[s] an einen kommerziellen Chatbot. Die technische Barriere ist effektiv verschwunden.
Krankenhaus-Netzwerke sind nicht Bereit
Die medizinische Bildgebungsinfrastruktur selbst verstärkt das Problem. DICOM, das Standardprotokoll zum Speichern und Teilen von Scans, wurde für Interoperabilität entworfen, nicht für Sicherheit. Eine 2023 Untersuchung der Cybersicherheitsfirma Aplite[s] fand über 3.800 DICOM-Server, die dem offenen Internet in 110 Ländern ausgesetzt waren und Daten von 16 Millionen Patienten preisgaben. Weniger als 1% dieser Server verwendeten effektive Sicherheitsmaßnahmen.
Die CT-GAN-Forscher von 2019 demonstrierten einen praktischen Angriffsvektor[s]: mit Erlaubnis drangen sie in ein echtes Krankenhaus-Netzwerk ein und fingen jeden Scan ab, der von einem CT-Gerät aufgenommen wurde. Interne Krankenhaus-Netzwerke übertragen oft Scans ohne Verschlüsselung, weil sie historisch nicht mit dem Internet verbunden waren. Diese Annahme ist zunehmend veraltet.
Was Getan Werden Kann
Forscher empfehlen eine geschichtete Verteidigung. Vorgeschlagene Schutzmaßnahmen umfassen unsichtbare Wasserzeichen[s], die zum Aufnahmezeitpunkt in Bilder eingebettet werden, und kryptographische Signaturen, die an den Technologen gebunden sind, der den Scan aufnahm. Diese würden eine Überwachungskette schaffen, die eine Manipulation nach der Aufnahme nachweisbar macht.
„Wir sehen potentiell nur die Spitze des Eisbergs“, warnte Tordjman[s]. „Der logische nächste Schritt in dieser Entwicklung ist die KI-Generierung synthetischer 3D-Bilder wie CT und MRI. Das Etablieren von Bildungsdatensätzen und Erkennungstools ist jetzt kritisch.“ Das Studienteam hat einen kuratierten Deepfake-Datensatz mit interaktiven Quiz[s] veröffentlicht, um Radiologen zu trainieren.
Bildintegritäts-Spezialistin Elisabeth Bik sagte es klar: „Das weckt Bedenken nicht nur für die Forschungsintegrität, sondern auch für klinische Arbeitsabläufe, Versicherungsansprüche und rechtliche Kontexte, in denen Bildbeweise verwendet werden.“[s]
Die verräterischen Zeichen existieren, vorerst. Deepfake Medizin Bilder sehen oft „zu perfekt“ aus, mit zu glatten Knochen, unnatürlich geraden Wirbelsäulen und verdächtig sauberen Frakturlinien. Aber während sich die Modelle verbessern, werden selbst diese Hinweise verschwinden.
Eine multizentrische Studie, die im März 2026 in Radiology veröffentlicht wurde[s], quantifiziert, was die Bildgebungsgemeinschaft befürchtet hat: Deepfake Medizin Bilder, die von kommerziell verfügbaren großen Sprachmodellen generiert wurden, sind nun in klinisch relevanten Raten von authentischen Radiographien ununterscheidbar. Weder menschliche Leser noch multimodale LLMs erreichten zuverlässige Diskriminierung, und die technische Barriere zur Produktion dieser Fälschungen ist nahe null gefallen.
Deepfake Medizin: Studiendesign und Ergebnisse
Die retrospektive diagnostische Genauigkeitsstudie[s], durchgeführt zwischen April und August 2025, rekrutierte 17 Radiologen aus 12 Institutionen in sechs Ländern mit Erfahrungen von 0 bis 40 Jahren. Sie bewerteten zwei sich nicht überschneidende Datensätze mit insgesamt 264 Bildern.
Datensatz 1 enthielt 77 authentische Radiographien gepaart mit 77 synthetischen Bildern, die von GPT-4o über mehrere anatomische Regionen (Brust, Extremitäten, Wirbelsäule) generiert wurden. Datensatz 2 enthielt 55 authentische Brustradiographien und 55 synthetische Brust-Röntgenbilder, produziert von RoentGen, einem latenten Diffusionsmodell, das auf Brustradiographien feinabgestimmt[s] und von Stanford Medicine-Forschern entwickelt wurde.
Die Studie lief in drei Phasen. In Phase 1 bewerteten Radiologen, blind für den Studienzweck, Bildqualität auf einer Likert-Skala und lieferten Diagnosen. Nur 41% (7 von 17) notierten spontan, dass KI-generierte Deepfake Medizin Bilder vorhanden sein könnten. Die diagnostische Genauigkeit betrug 91,3% für authentische Radiographien und 92,4% für synthetische[s], was bestätigte, dass Deepfake Medizin Bilder nicht nur visuell überzeugend, sondern auch diagnostisch kohärent waren.
In Phase 2, informiert dass synthetische Bilder vorhanden waren, erreichten Radiologen eine mittlere Genauigkeit von 75% (95% CI: 68-81%) auf dem GPT-4o-Datensatz. Individuelle Leistung reichte von 58% bis 92%. Gepoolte Sensitivität war 69,1% und Spezifität 80,4%. In Phase 3 betrug die Genauigkeit auf dem RoentGen-Datensatz 70% (95% CI: 62-78%), ohne statistisch signifikanten Unterschied zur GPT-4o-Leistung (P = .07).
Keine Korrelation wurde zwischen Erfahrungsjahren und Erkennungsgenauigkeit gefunden.[s] Muskuloskelettale Radiologen übertrafen andere Subspezialisten signifikant, wahrscheinlich weil Knochenmorphologie diskretere strukturelle Hinweise als Weichgewebsmuster liefert.
LLM-Leistung als Diskriminatoren
Vier multimodale LLMs wurden auf derselben Klassifikationsaufgabe evaluiert. GPT-4o erreichte 85% Genauigkeit auf seinen eigenen synthetischen Bildern[s] und 75,5% auf RoentGen-Bildern. GPT-5 erzielte 82,5% bzw. 89,1%. Llama 4 Maverick (59%, 52%) und Gemini 2.5 Pro (56%, 57%) performten substantiell schlechter, in manchen Fällen nahe dem Zufallslevel. Der Unterschied zwischen OpenAI-Modellen und Konkurrenten war statistisch signifikant (alle P < .001).
Die Tatsache, dass GPT-4o seine eigene Ausgabe nicht zuverlässig identifizieren konnte, ist bedeutsam. Es deutet darauf hin, dass der Generierungsprozess keine leicht wiedergewinnbaren Artefakte einbettet: Das Modell generiert aus derselben gelernten Verteilung radiographischer Merkmale, was Diskriminierung zu einem fundamental schwierigeren Problem als Generierung macht.
Von GANs zu LLMs: Der Zugänglichkeits-Wendepunkt
Die aktuelle Studie repräsentiert einen Wendepunkt in der Evolution von Deepfake Medizin. Generative KI in medizinischer Bildgebung hat sich von GANs zu diffusionsbasierten Modellen entwickelt[s] und nun zu allzweck-LLMs, die natürlichsprachliche Eingaben akzeptieren. Jede Generation senkte die erforderliche Expertise.
Das CT-GAN-Framework von 2019 der Ben-Gurion-Universität demonstrierte die Bedrohung in volumetrischer Bildgebung. Mirsky et al. verwendeten ein 3D-konditionelles GAN, um Lungenkrebs in CT-Scans zu injizieren und zu entfernen[s], was Manipulationen erreichte, die in Millisekunden ausführten und Radiologen in einer blinden Bewertung täuschten. Drei Radiologen fehldiagnostizierten 99% der Scans mit injizierten Tumoren und 94% derer mit entfernten Tumoren.[s] Selbst nach Information über die Manipulation blieben Fehldiagnose-Raten bei 60% und 87%.
Aber CT-GAN erforderte Training benutzerdefinierter cGAN-Architekturen auf kuratierten medizinischen Datensätzen, eine nichttriviale Pipeline. Die 2026-Studie zeigt, dass vergleichbare 2D-Täuschung nun durch einen kommerziellen API-Aufruf erreichbar ist. Die Angriffsfläche hat sich von staatlichen Akteuren und gut finanzierten Gegnern auf im Wesentlichen jeden erweitert.
Infrastruktur-Verwundbarkeiten: DICOM und PACS
Die Bildgebungsinfrastruktur selbst bleibt schlecht verteidigt. DICOM (Digital Imaging and Communications in Medicine), der universelle Standard für medizinische Bildspeicherung und -übertragung, wurde für Interoperabilität, nicht für Sicherheit entworfen[s]. PACS (Picture Archiving and Communication Systems) Server operieren häufig mit minimaler Authentifizierung und unverschlüsselter interner Kommunikation.
Ein 2023-Audit von Aplite, präsentiert auf der Black Hat Europe[s], identifizierte über 3.800 exponierte DICOM-Server in über 110 Ländern mit 16 Millionen Patientenakten und 43 Millionen Gesundheitsakten, die vom offenen Internet zugänglich waren. Weniger als 1% implementierten effektive Sicherheitsmaßnahmen. Die Forscher demonstrierten auch einen neuen Angriffsvektor für Datenmanipulation innerhalb existierender medizinischer Bilder auf diesen exponierten Systemen.
Das CT-GAN-Team demonstrierte einen Man-in-the-Middle-Abfangangriff auf ein lebendes Krankenhaus-Netzwerk[s], der jeden Scan von einem CT-Gerät erfasste. Interne Radiologie-Netzwerke nahmen historisch Air-Gapping vom Internet an, aber Cloud-Migration und Remote-Zugriffs-Anforderungen haben diese Annahme erodiert.
Minderungsstrategien
Die Studienautoren schlagen eine mehrschichtige Verteidigung vor[s]: unsichtbare Wasserzeichen, die bei der Bildakquisition eingebettet werden, technologen-verknüpfte kryptographische Signaturen bei der Aufnahme angehängt, PACS-Audit-Logging für Datenzugriffsmuster und Anomalie-Erkennung für ungewöhnliche Datensatz-Modifikationen.
Die Radiologen in der Studie identifizierten mehrere morphologische Anzeichen in aktuellen Deepfake Medizin Bildern: bilaterale Symmetrie-Artefakte, einheitliche Rauschmuster (denen das räumlich variierende Rauschen echter Detektor-Hardware fehlt), zu glatter Knochen-Kortex, unnatürlich regelmäßige Wirbel-Ausrichtung und Frakturlinien, die „zu sauber“ erscheinen, oft nur eine kortikale Oberfläche betreffend, anstatt durch den vollen Knochen-Querschnitt zu propagieren.
Jedoch sind diese Signaturen modell-spezifisch und werden wahrscheinlich abnehmen, wenn sich generative Architekturen verbessern. „Wir sehen potentiell nur die Spitze des Eisbergs“, notierte Tordjman[s]. „Der logische nächste Schritt in dieser Evolution ist KI-Generierung synthetischer 3D-Bilder wie CT und MRI.“
Elisabeth Bik, eine Bildintegritäts-Spezialistin, nannte die Befunde „sowohl störend als auch nicht sehr überraschend“[s], und notierte, dass die Implikationen über die klinische Praxis hinaus zu „Forschungsintegrität, Versicherungsansprüchen und rechtlichen Kontexten reichen, wo Bildbeweise verwendet werden“. Das Studienteam hat einen kuratierten Bildungsdatensatz auf noneedanick.github.io/DeepFakeXRay[s] veröffentlicht, um Kliniker in der Erkennung zu trainieren.
Die fundamentale Herausforderung ist asymmetrisch: einen überzeugenden Deepfake zu generieren ist rechnerisch billig und wird billiger. Einen zu erkennen erfordert entweder kryptographische Provenienz (die Infrastruktur-Überholung verlangt) oder visuelle Forensik (die die Studie als unzuverlässig selbst unter Experten zeigt). Das Fenster für proaktive Verteidigung verengt sich.