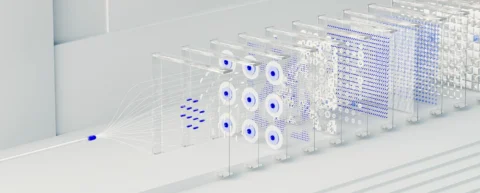
Wenn Sie eine Frage in ChatGPT eingeben oder Ihr Smartphone bitten, einen Timer zu stellen, wandelt Textverarbeitungssoftware Sprache in maschinenlesbare Darstellungen um. In modernen Sprachmodellen werden diese Darstellungen mit Mustern verglichen, die aus großen Textkorpora gelernt wurden, um Output zu erzeugen, der menschlich klingen kann. Die Mechanik der natürlichen Sprachverarbeitung hinter dieser Transformation zu verstehen, offenbart sowohl den Einfallsreichtum moderner KI als auch ihre grundlegenden Grenzen.
Dieser Prozess lässt sich in fünf Kernstufen verstehen, von denen jede ein spezifisches Problem bei der Darstellung und Transformation von Sprache löst. Moderne Transformer-Systeme werden nicht allein aus handcodierten Grammatikregeln aufgebaut; sie erlernen statistische Muster aus enormen Textmengen.
Schritt 1: Die Tokenisierung zerlegt Text in Teile
Computer können Rohtext nicht direkt verarbeiten. Der erste Schritt in der Mechanik der natürlichen Sprachverarbeitung ist die Tokenisierung: das Aufteilen eines Satzes in diskrete Einheiten, die Token genannt werden.[s] Ein Token kann je nach System ein ganzes Wort, ein Wortbestandteil oder sogar ein einzelnes Zeichen sein.
Ein verbreiteter Ansatz, Byte Pair Encoding (BPE), entstand ursprünglich als Datenkomprimierungstechnik, bevor er für die Tokenisierung von Sprachmodellen adaptiert wurde.[s] BPE beginnt mit Bytes oder Zeichen und führt iterativ die häufigsten Paare zusammen, bis eine Zielvokabulargröße erreicht ist.
Betrachten Sie den Satz „unhappiness is common.“ BPE könnte „unhappiness“ in „un,“ „happiness,“ oder sogar „un,“ „happ,“ „iness,“ aufteilen, je nachdem, welche Muster in den Trainingsdaten am häufigsten auftraten. Diese Flexibilität ermöglicht es Modellen, bisher unbekannte Wörter zu verarbeiten, indem sie diese in vertraute Bestandteile zerlegen.
Die Wahl des Vokabulars ist von enormer Bedeutung. Eine Forschungsgruppe formulierte es so: Das Vokabular „muss die Kodierung ausreichend semantischer Informationen aus einem Text ermöglichen, um die Aufgaben der natürlichen Sprachverarbeitung zu erfüllen, für die das Modell konzipiert ist.“[s] Ein zu kleines Vokabular erzwingt ungeschickte Aufteilungen; ein zu großes verschwendet Rechenressourcen für seltene Token.
Leerzeichen stellen ein überraschend heikles Problem dar. Englischsprachige gehen davon aus, dass Leerzeichen Wörter zuverlässig trennen, doch diese Annahme versagt in anderen Sprachen und sogar im Englischen selbst. Mehrwortausdrücke wie „by the way“ oder „search engine“ fungieren als einzelne semantische Einheiten.[s] Chinesisch und Japanisch verwenden oft keine Leerzeichen zwischen Wörtern. Jüngere Forschungen zu „Superwort“-Tokenizern, die Leerzeichengrenzen überbrücken, erzielten durchschnittlich bis zu 33 % weniger Token bei gleichzeitiger Verbesserung der Modellleistung um 4,0 % über 30 Benchmark-Aufgaben hinweg.[s]
Schritt 2: Einbettung wandelt Token in Vektoren um
Sobald Text tokenisiert ist, wird jeder Token-Index einem gelernten Vektor zugeordnet: einer Liste von Zahlen, die das Modell zur Vorhersage und Verknüpfung von Token verwendet.[s] In diesem Einbettungsschritt prägt Sprache die Wahrnehmung des Modells. Token, die in ähnlichen Kontexten vorkommen, landen oft in benachbarten Bereichen des Einbettungsraums.
Moderne große Sprachmodelle verwenden Einbettungsdimensionen im Tausenderbereich. Die 70-Milliarden-Parameter-Version von Llama 3 verwendet 8.192-dimensionale Vektoren; die 27-Milliarden-Parameter-Version von Gemma 3 verwendet 5.376 Dimensionen.[s] Die Darstellung als Ganzes erfasst gelernte Merkmale, wenngleich Forscher einzelnen Komponenten oft keine stabile menschliche Bedeutung zuordnen können.
Position und Kontext spielen ebenfalls eine Rolle. Dasselbe Token kann in Phrasen wie „river bank“ und „bank account“ unterschiedliche Bedeutungen tragen, und spätere Attention-Schichten helfen bei der Disambiguierung. Frühere Systeme fügten Positionsinformationen direkt zu den Token-Einbettungen hinzu; moderne Architekturen wie Llama wenden Positionskodierung innerhalb des Attention-Mechanismus selbst durch eine Technik namens Rotary Positional Embeddings an.[s]
Schritt 3: Attention ermöglicht Token die Kommunikation
Die Mechanik der natürlichen Sprachverarbeitung im Bereich der Attention stellt „einen grundlegenden Paradigmenwechsel in neuronalen Netzarchitekturen dar, der Modelle in die Lage versetzt, sich durch gelernte Gewichtungsfunktionen selektiv auf relevante Teile von Eingabesequenzen zu konzentrieren.“[s] Vor Attention-basierten Transformern verarbeiteten viele Sequenzmodelle Text sequenziell und hatten Schwierigkeiten, weit voneinander entfernte Wörter in einem Satz zu verbinden.
Attention funktioniert wie eine Datenbankabfrage. Jedes Token erzeugt drei Dinge: eine Anfrage (Query, wonach es sucht), einen Schlüssel (Key, was es anbietet) und einen Wert (Value, die Informationen, die es trägt). Das System vergleicht jede Anfrage mit allen Schlüsseln, gewichtet die Ergebnisse und kombiniert die entsprechenden Werte.[s] Bei der Verarbeitung des Wortes „it“ in „The cat sat on the mat because it was tired“ ermöglicht Attention dem „it“, zurückzublicken und festzustellen, dass es sich auf „cat“ und nicht auf „mat“ bezieht.
Moderne Transformer verwenden „Multi-Head-Attention“ und führen mehrere Attention-Operationen parallel aus. Jeder Kopf kann sich auf unterschiedliche Beziehungen konzentrieren: einer verfolgt möglicherweise grammatische Kongruenz, ein anderer semantische Ähnlichkeit, ein dritter Positionsmuster. Die Attention-Köpfe „lesen Informationen aus dem Residualstrom vorheriger Token über die Query-Key-Unterraumprojektionen und schreiben die aufgenommenen Informationen dann an die aktuelle Position zurück.“[s]
Der „Residualstrom“ verdient hier besondere Erwähnung. Er fungiert als „zentrale Autobahn für die Informationsweitergabe“ und bewahrt einen gemeinsamen Speicherzustand, den jede Schicht aktualisiert.[s] Residualverbindungen helfen außerdem dabei, Informationen und Gradienten durch tiefe Netzwerke zu leiten.
Schritt 4: Feed-Forward-Netzwerke speichern Wissen
Zwischen den Attention-Schichten befinden sich Feed-Forward-Netzwerke (FFNs), die Forscher zunehmend als Wissensspeicher des Modells betrachten. FFNs „werden oft als Schlüssel-Wert-Speicher konzeptualisiert, bei denen die erste Schicht den Strom in einen hochdimensionalen Zustand projiziert (Muster erkennt oder ‚Wissensschlüssel‘) und die zweite Schicht das abgerufene Wissen zurück in den Strom schreibt.“[s]
Wenn Sie ein Sprachmodell fragen, wer Hamlet geschrieben hat, hilft der Attention-Mechanismus dabei, Beziehungen in der Frage darzustellen, während Feed-Forward-Schichten oft als Speicher oder Abrufmechanismus für Fakten modelliert werden, wie etwa dass Shakespeare Hamlet schrieb. Diese Arbeitsteilung, Attention für Beziehungen und FFNs für Fakten, erklärt, warum Modelle beim Schlussfolgern überraschend gut sein können, während sie gleichzeitig sachliche Fehler machen (und umgekehrt).
Schritt 5: Ausgabeerzeugung
Nachdem der finale Vektor den Stapel aus Attention- und FFN-Schichten durchlaufen hat, wird er in eine Wahrscheinlichkeitsverteilung über das Vokabular zurückkonvertiert. Das Modell weist jedem möglichen nächsten Token eine Wahrscheinlichkeit zu, von häufigen Wörtern bis hin zu seltenen Symbolen. Während der Generierung wird aus dieser Verteilung gesampelt (oder die Option mit der höchsten Wahrscheinlichkeit gewählt), und der gesamte Prozess wiederholt sich für das nächste Token.
Diese autoregressive Generierung, bei der jeweils ein Token vorhergesagt wird, erklärt sowohl die Flüssigkeit als auch die Fehlerquellen moderner Sprachmodelle. Jede Vorhersage bedingt alle vorherigen Token und erhält so die Kohärenz über lange Passagen hinweg. Fehler verstärken sich jedoch: Ein früher Irrtum kann eine gesamte Antwort aus der Bahn werfen.
Mechanik der natürlichen Sprachverarbeitung: Die Grenzen
Das Verständnis dieser Mechanik der natürlichen Sprachverarbeitung offenbart Einschränkungen, mit denen Forscher auch bei der Skalierung von Modellen noch ringen.
Attention hat quadratische Komplexität: Die Verarbeitung einer Sequenz der Länge n erfordert O(n²d) Operationen, wobei d die Einbettungsdimension ist.[s] Verdoppeln Sie die Kontextlänge, vervierfacht sich dieser Teil der Berechnung. Das ist ein Grund, warum die Modellierung langer Kontexte rechnerisch aufwendig bleibt und warum Forscher weiterhin „effiziente Attention“-Varianten verfolgen.
Philosophisch beunruhigender ist, dass diese Systeme Blackboxen bleiben. „Unser theoretisches Verständnis von LLMs ist nach wie vor unverhältnismäßig wenig entwickelt, sodass diese Systeme weitgehend als Blackboxen behandelt werden müssen. Sie funktionieren außergewöhnlich gut, doch ihre internen Betriebsmechanismen, das Wie und Warum ihrer Wirksamkeit, bleiben schwer fassbar.“[s]
Manche Forscher haben untersucht, ob Sprachmodelle so etwas wie eine Theory of Mind entwickeln, also die Fähigkeit, das Wissen und die Überzeugungen anderer zu modellieren, eine Fähigkeit, die bei menschlichen Kindern um das vierte Lebensjahr herum entsteht. Die Belege bleiben widersprüchlich; Modelle können manche Theory-of-Mind-Tests bestehen, während sie andere auf eine Weise scheitern lassen, die eher auf oberflächliches Mustererkennen als auf menschliches Schlussfolgern hindeutet.[s]
Vielleicht am überraschendsten ist, dass Sprachmodelle mit Grammatikalität auf eine Weise kämpfen, die ihre flüssigen Ausgaben verschleiern. „Sprachmodelle weisen ungrammatischen Sätzen nicht kategorisch geringere Wahrscheinlichkeiten zu als grammatischen, und das ist auch nicht so beabsichtigt; LM-Wahrscheinlichkeiten eignen sich im Allgemeinen schlecht zur Unterscheidung grammatischer von ungrammatischen Sätzen.“[s] Sie können grammatisch korrekten Text erzeugen, obwohl ihre rohen Wahrscheinlichkeiten kein zuverlässiger Grammatikalitätstest sind.
Jüngste MIT-Forschungen haben ergeben, dass Modelle Grammatikalitätsinformationen tatsächlich kodieren, jedoch nicht in ihren Ausgabewahrscheinlichkeiten. „Sprachmodelle erwerben in gewissem Maße eine implizite Grammatikalitätsunterscheidung in ihren verborgenen Schichten“, die über spezialisierte Probes zugänglich ist, nicht aber über den Standardgenerierungsprozess.[s]
Das Problem emergenter Intelligenz
Wenn Modelle skaliert werden, treten einige Fähigkeiten und Fehlerformen stärker hervor oder nehmen neue Formen an: In-Context-Learning, Skalierungsgesetz-Verhalten und plötzliche „Aha-Momente“ während des Trainings. Halluzinationen selbst sind nicht ausschließlich auf große Modelle beschränkt; sie treten in der gesamten neuronalen Sprachgenerierung auf, nehmen jedoch bei großen Modellen neue Formen an.[s] Diese „emergenten Phänomene“ entziehen sich der Vorhersage und Erklärung; sie treten an Skalierungsschwellen auf, die Forscher nicht zuverlässig vorhersagen können.
Die Datenzusammensetzung prägt diese Fähigkeiten auf eine Weise, die Forscher erst beginnen zu verstehen. Modelle, die auf Mischungen aus Webtexten, Büchern, Code und wissenschaftlichen Artikeln trainiert werden, übertreffen solche, die auf einer einzigen Quelle trainiert wurden.[s] Warum vielfältige Trainingsdaten leistungsfähigere Modelle erzeugen, bleibt eine offene Frage, obwohl es wahrscheinlich mit der Übertragung von Schlussfolgerungsmustern über Domänen hinweg zusammenhängt.
Allgemeine Berechenbarkeitsresultate wie Rices Theorem begrenzen, was automatisch über das Verhalten beliebiger Programme bewiesen werden kann.[s] Offene neuronale Systeme erben eine Version dieses Problems. Praktische Verifikation kann begrenzte Eigenschaften beweisen, aber sie kann nicht mathematisch verifizieren, dass ein Sprachmodell nie halluziniert, nie schädliche Inhalte erzeugt oder in sicherheitskritischen Anwendungen nie versagt.[s]
Was das bedeutet
Die hier beschriebene Mechanik der natürlichen Sprachverarbeitung verkörpert eine spezifische Wette: dass statistische Muster über Token große Mengen expliziter linguistischer Ingenieursarbeit ersetzen können. Diese Wette hat sich außerordentlich ausgezahlt. Modelle, die darauf trainiert wurden, das nächste Wort vorherzusagen, haben Verhaltensweisen gelernt, die mit Grammatik, Fakten, Schlussfolgerungsmustern und stilistischen Konventionen übereinstimmen, und das alles ohne explizite Anleitung in jedem dieser Bereiche.
Die Mechanismen bleiben jedoch dem menschlichen Sprachverarbeitungsprozess fremd. Wir denken nicht in Attention-Gewichten oder Feed-Forward-Aktivierungen. Die Konvergenz der Fähigkeiten, KI-Systeme, die menschenähnliche Sprache erzeugen, impliziert keine Konvergenz der Mechanismen. Das Verständnis der Mechanik der natürlichen Sprachverarbeitung hinter diesen Systemen hilft uns, sowohl ihre Errungenschaften als auch ihre inhärenten Grenzen zu würdigen.
Moderne Sprachmodelle transformieren Text durch eine Pipeline gelernter Transformationen in kontinuierliche Darstellungen: Tokenisierung, Einbettung, Attention, Feed-Forward-Netzwerke und Ausgabeprojektion. Jede Stufe implementiert spezifische induktive Biases, die statistisches Sprachmodellieren in großem Maßstab ermöglichen. Die Mechanik der natürlichen Sprachverarbeitung, die diesen Transformationen zugrunde liegt, bestimmt sowohl die Fähigkeiten als auch die Fehlerquellen Transformer-basierter Systeme.
Tokenisierung: Subwort-Dekomposition
Die Mechanik der natürlichen Sprachverarbeitung beginnt mit der Tokenisierung, der Umwandlung von Zeichen- oder Bytesequenzen in diskrete Token aus einem festen Vokabular. Zeitgenössische Systeme verwenden gewöhnlich Subwort-Tokenisierung, oft Byte Pair Encoding (BPE) oder Varianten wie WordPiece. Wie es im SuperBPE-Paper heißt, „segmentieren Tokenizer einen Bytestrom in eine Sequenz von Token im LM-Vokabular.“[s]
BPE entstand ursprünglich als Datenkomprimierungsalgorithmus und wurde für NLP adaptiert; das SuperBPE-Paper vermerkt, dass „der Algorithmus 1994 im Bereich der Datenkomprimierung entstanden ist.“[s] Im Standard-BPE-Training werden die Häufigkeiten benachbarter Token-Paare erfasst, das häufigste Paar zu einem neuen Token zusammengeführt, und der Prozess wiederholt sich, bis das Vokabular die Zielgröße erreicht.
Die Vokabularauswahl beinhaltet Abwägungen. Das Vokabular „muss die Kodierung ausreichend semantischer Informationen aus einem Text ermöglichen, um, bei gegebenem Modell, die Aufgaben der natürlichen Sprachverarbeitung zu erfüllen, für die dieses Modell konzipiert ist.“[s] Größere Vokabulare verkürzen Sequenzlängen, erhöhen aber die Einbettungsparameter und die Sparsity bei seltenen Token.
Standard-BPE setzt Leerzeichengrenzen durch und verhindert so Token, die Wortgrenzen überschreiten. Diese Annahme versagt bei Sprachen ohne Leerzeichentrennzeichen. „Leerzeichen ist kein zuverlässiger Bedeutungstrennzeichen, wie Mehrwortausdrücke (z.B. by the way), sprachübergreifende Variation in der Anzahl der Wörter zur Ausdrucksweise eines Konzepts und Sprachen, die überhaupt keine Leerzeichen verwenden, belegen.“[s]
Jüngere Arbeiten zu SuperBPE lockern die Subwortbeschränkung durch einen Lehrplan: zuerst werden Subwörter mit Leerzeichen-Pretokenisierung gelernt, dann Superwörter ohne diese. Dies erzielt „durchschnittlich bis zu 33 % weniger Token als BPE“ bei gleichzeitiger Verbesserung der Downstream-Leistung um 4,0 % über 30 Aufgaben und Reduzierung des Inferenz-Compute um 27 bis 33 %.[s] Die Effizienzgewinne ergeben sich aus der Erfassung von Mehrwortausdrücken als einzelne Token: „SuperBPE-Token entsprechen oft Mehrwortausdrücken im Englischen, d.h. Wortsequenzen, die als einzelne semantische Einheit fungieren.“[s]
Einbettung: Token-zu-Vektor-Abbildung
„Moderne Methoden der natürlichen Sprachverarbeitung, die auf Attention-Mechanismen basieren, verarbeiten textuelle Informationen nicht in Form von Zeichenketten, sondern als Vektorsequenzen.“[s] Die Einbettungsschicht bildet jeden Token-Index auf einen gelernten Vektor ab. Zeitgenössische Modelle verwenden hochdimensionale Einbettungen: Llama 3 70B verwendet d=8192, Gemma 3 27B verwendet d=5376.[s]
Positionskodierung adressiert die Permutationsäquivarianz der Self-Attention. „Die Permutationsäquivarianz-Eigenschaft der Self-Attention wird bewiesen, und ihre Implikationen für die Positionskodierung werden eingehend untersucht.“[s] Ohne Positionsinformationen kann das Modell „dog bites man“ nicht von „man bites dog“ unterscheiden. Frühe Transformer fügten sinusoidale Positionseinbettungen am Eingang hinzu; moderne Architekturen wie Llama verwenden Rotary Positional Embeddings (RoPE) und wenden positionsabhängige Rotationen auf Query- und Key-Vektoren innerhalb der Attention an.
Das Verständnis, wie Einbettungsgeometrie mit Semantik zusammenhängt, ist aktiver Forschungsgegenstand. Wie Sprache die Wahrnehmung auf Einbettungsebene prägt, ob ähnliche Einbettungen ähnliche Bedeutungen im menschlichen Sinne widerspiegeln, wirft komplexe Fragen über die Beziehung zwischen statistischer Kookkurrenz und genuiner Semantik auf.
Attention: Inhaltsbasiertes Informationsrouting
„Attention-Mechanismen stellen einen grundlegenden Paradigmenwechsel in neuronalen Netzarchitekturen dar, der Modelle in die Lage versetzt, sich durch gelernte Gewichtungsfunktionen selektiv auf relevante Teile von Eingabesequenzen zu konzentrieren.“[s] Skalierte Skalarprodukt-Attention berechnet:
Attention(Q, K, V) = softmax(QK^T / sqrt(d_k)) V
wobei Q, K, V Query-, Key- und Value-Projektionen der Eingabe sind und d_k die Key-Dimension ist.
„Attention-Mechanismen, die Bausteine der Transformer-Architektur, ermöglichen die Kodierung semantischer Informationen zwischen Token durch eine datenbankähnliche Struktur. Eine Datenbank kann als eine Menge von (Schlüssel, Wert)-Tupeln betrachtet werden, sodass die Datenbank bei einer Query q den Wert v zurückgibt, der mit dem Tupel verknüpft ist, dessen Schlüssel der Query entspricht.“[s]
Multi-Head-Attention führt H parallele Attention-Operationen mit separaten gelernten Projektionen aus und konkateniert und projiziert die Ergebnisse. Dadurch können sich verschiedene Köpfe auf unterschiedliche Beziehungstypen spezialisieren. „Attention-Köpfe lesen Informationen aus dem Residualstrom vorheriger Token über die Query-Key-Unterraumprojektionen und schreiben die aufgenommenen Informationen dann über die Value- und Output-Projektionen an die aktuelle Position zurück.“[s]
Die Residualstrom-Architektur, bei der jede Schicht ihre Ausgabe zu einer laufenden Summe addiert, ermöglicht Gradientenfluss und kompositionelle Merkmalskonstruktion. „Der Residualstrom fungiert als zentrale Autobahn für die Informationsweitergabe. Er bewahrt einen gemeinsamen Speicherzustand, der iterativ durch die Blöcke aktualisiert wird.“[s]
Die Berechnungskomplexität beträgt O(n²d) für Sequenzlänge n und Dimension d.[s] Diese quadratische Skalierung mit der Sequenzlänge bleibt ein wesentlicher Engpass für die Modellierung langer Kontexte und hat umfangreiche Forschungen zu spärlichen und linearen Attention-Varianten motiviert.
Feed-Forward-Netzwerke: Musteraktivierter Wissensabruf
Jeder Transformer-Block verschränkt Attention mit einem positionsweisen Feed-Forward-Netzwerk. „Feed-Forward-Netzwerke werden oft als Schlüssel-Wert-Speicher konzeptualisiert, bei denen die erste Schicht den Strom in einen hochdimensionalen Zustand projiziert (Muster erkennt oder ‚Wissensschlüssel‘) und die zweite Schicht das abgerufene Wissen zurück in den Strom schreibt.“[s]
Das Standard-FFN wendet an:
FFN(x) = W_2 * activation(W_1 * x)
wobei die Zwischendimension in Standard-Transformer-Formulierungen oft größer ist als die Modelldimension. Moderne Varianten wie SwiGLU fügen Gating-Mechanismen hinzu. Die erste Projektion kann als Abgleich von Eingangsmustern mit gelernten „Wissensschlüsseln“ interpretiert werden; die zweite Projektion ruft das zugehörige Wissen ab.
Dieser Rahmen legt nahe, dass Attention die Beziehungsberechnung übernimmt, während FFNs faktisches Wissen speichern, obwohl die Grenze in der Praxis verschwimmt. Mechanistische Interpretierbarkeitsforschung versucht, spezifische Fakten auf spezifische Neuronen zu lokalisieren, mit gemischtem Erfolg.
Mechanik der natürlichen Sprachverarbeitung: Grundlegende Einschränkungen
Trotz empirischer Erfolge „bleibt unser theoretisches Verständnis von LLMs unverhältnismäßig wenig entwickelt, sodass diese Systeme weitgehend als Blackboxen behandelt werden müssen. Sie funktionieren außergewöhnlich gut, doch ihre internen Betriebsmechanismen, das Wie und Warum ihrer Wirksamkeit, bleiben schwer fassbar.“[s]
Mehrere emergente Phänomene entziehen sich der theoretischen Erklärung: „LLMs weisen zahlreiche emergente Phänomene auf, die in kleineren Modellen nicht auftreten, wie Halluzinationen, In-Context-Learning (ICL), Skalierungsgesetze und plötzliche ‚Aha-Momente‘ während des Trainings.“[s] Diese Fähigkeiten können aus kleineren Modellen schwer vorherzusagen sein.
Datenzusammensetzung ist wichtig. „Modelle, die auf einer sorgfältig kuratierten Mischung von Daten aus mehreren Quellen trainiert werden (z.B. Webtexte, Bücher, Code, wissenschaftliche Artikel), übertreffen konsistent solche, die auf monolithischen Korpora trainiert wurden.“[s] Die theoretische Begründung für die Wirksamkeit von Mischungen bleibt unvollständig.
Grammatikalität stellt eine überraschende Lücke dar. „Sprachmodelle weisen ungrammatischen Sätzen nicht kategorisch geringere Wahrscheinlichkeiten zu als grammatischen, und das ist auch nicht so beabsichtigt; LM-Wahrscheinlichkeiten eignen sich im Allgemeinen schlecht zur Unterscheidung grammatischer von ungrammatischen Sätzen.“[s] Modelle können fließenden Text erzeugen, obwohl die rohe Zeichenkettenwahrscheinlichkeit kein zuverlässiges Grammatikalitätsurteil ist.
Probing-Experimente enthüllen implizites grammatisches Wissen. „Eine lineare Probe, die auf synthetischen Perturbationsdaten trainiert wurde, kann wahrscheinlichkeitsbasierte Grammatikalitätsurteile sowohl in Minimal-Paar- als auch in Nicht-Minimal-Paar-basierten Grammatikalitätsurteil-Benchmarks übertreffen.“[s] Die Grammatikalitätsunterscheidung existiert in verborgenen Darstellungen, auch wenn sie in Ausgabewahrscheinlichkeiten nicht vorhanden ist: „Sprachmodelle erwerben in gewissem Maße eine implizite Grammatikalitätsunterscheidung in ihren verborgenen Schichten.“[s]
Manche Forscher untersuchen, ob Sprachmodelle eine Theory of Mind entwickeln, also die Fähigkeit, die Überzeugungen und Wissenszustände anderer zu modellieren. Die Belege sind gemischt; Modelle bestehen manche False-Belief-Tests, während sie andere scheitern lassen, was darauf hindeutet, dass sie möglicherweise oberflächliche Korrelate ausnutzen statt echte mentale Zustandszuschreibung zu besitzen.[s]
Formale Verifikation kann begrenzte Eigenschaften bestimmter Systeme beweisen, aber allgemeine Berechenbarkeitsschranken wie Rices Theorem verhindern automatische Beweise für das Verhalten beliebiger Programme.[s] Offene Sprachmodelle erben eine Version dieser Grenze: Wir können nicht mathematisch verifizieren, dass ein Modell nie halluziniert, nie schädlichen Output erzeugt oder stets korrekt schlussfolgert.[s]
Der Weg nach vorne
Die hier beschriebene Mechanik der natürlichen Sprachverarbeitung verkörpert eine spezifische Hypothese: dass autoregressive Vorhersage über Token, ausreichend skaliert, nützliches Sprachverhalten hervorbringen kann. Diese Hypothese hat sich als außerordentlich fruchtbar erwiesen und Systeme hervorgebracht, die Fachprüfungen bestehen, funktionierenden Code schreiben und erweiterte Dialoge führen.
Dennoch besteht die Lücke zwischen empirischer Leistungsfähigkeit und theoretischem Verständnis fort. Wir können beschreiben, was Attention berechnet, aber nicht erklären, warum spezifische Attention-Muster entstehen. Wir können messen, dass Datenmischungen die Leistung verbessern, aber optimale Mischungsverhältnisse nicht aus ersten Prinzipien ableiten. Die Mechanik der natürlichen Sprachverarbeitung von Transformern ist mathematisch gut spezifiziert, bleibt aber als kognitives oder linguistisches System undurchsichtig.